
NVIDIA Nemotron 3 Nano 30B-A3B is Now Available on HexGrid.cloud

NVIDIA Nemotron 3 Nano 30B-A3B is now available for dedicated deployment on a GPU of your choice on HexGrid.cloud. Run in One-click and get an OpenAI-compatible endpoint.
Nemotron 3 Nano is a 30B-class open model from NVIDIA built for efficient reasoning, coding, chat, agentic workflows, and long-context applications. It uses a hybrid Mixture-of-Experts architecture, activating only a small fraction of its total parameters per token, which makes it especially attractive for teams that want strong reasoning performance without the operational cost of serving much larger dense models.
Why Nemotron 3 Nano matters
NVIDIA describes Nemotron as a family of open models with open weights, training data, and recipes designed for building specialized AI agents.[¹]
Nemotron 3 Nano is the compact, efficiency-focused model in the Nemotron 3 family. It is designed for teams that need a practical balance of reasoning quality, inference throughput, long-context support, and deployment cost.
The model is especially interesting because it combines three important ideas:
Reasoning and non-reasoning in one model
Nemotron 3 Nano can generate reasoning traces before producing its final answer, and this behavior can be controlled through the chat template.[²]Hybrid Mamba-Transformer MoE architecture
NVIDIA’s model card describes the model as a hybrid architecture with Mamba-2, attention, and Mixture-of-Experts layers. It has 30B-class total parameters while activating only around 3B-class parameters per token.[²]Long-context support up to 1M tokens
NVIDIA’s Nemotron 3 research page highlights long-context support up to 1M tokens, making the model relevant for large documents, retrieval-heavy workflows, agent memory, codebases, logs, and enterprise knowledge tasks.[³]
This is what makes Nemotron 3 Nano compelling: it is not just a smaller model. It is a model designed to make advanced reasoning more practical to deploy.
Press enter or click to view image in full size
Model Snapshot
Press enter or click to view image in full size

Benchmark highlights
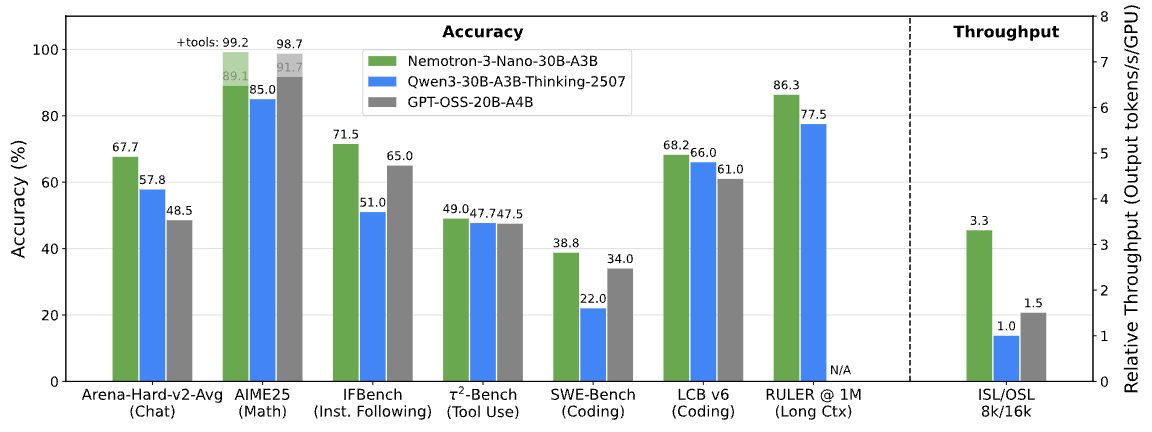
NVIDIA’s published benchmark table compares Nemotron 3 Nano 30B-A3B-BF16 against Qwen3–30B-A3B-Thinking-2507 and GPT-OSS-20B across reasoning, coding, agentic, instruction-following, long-context, and multilingual tasks.
Reasoning and coding performance
Press enter or click to view image in full size
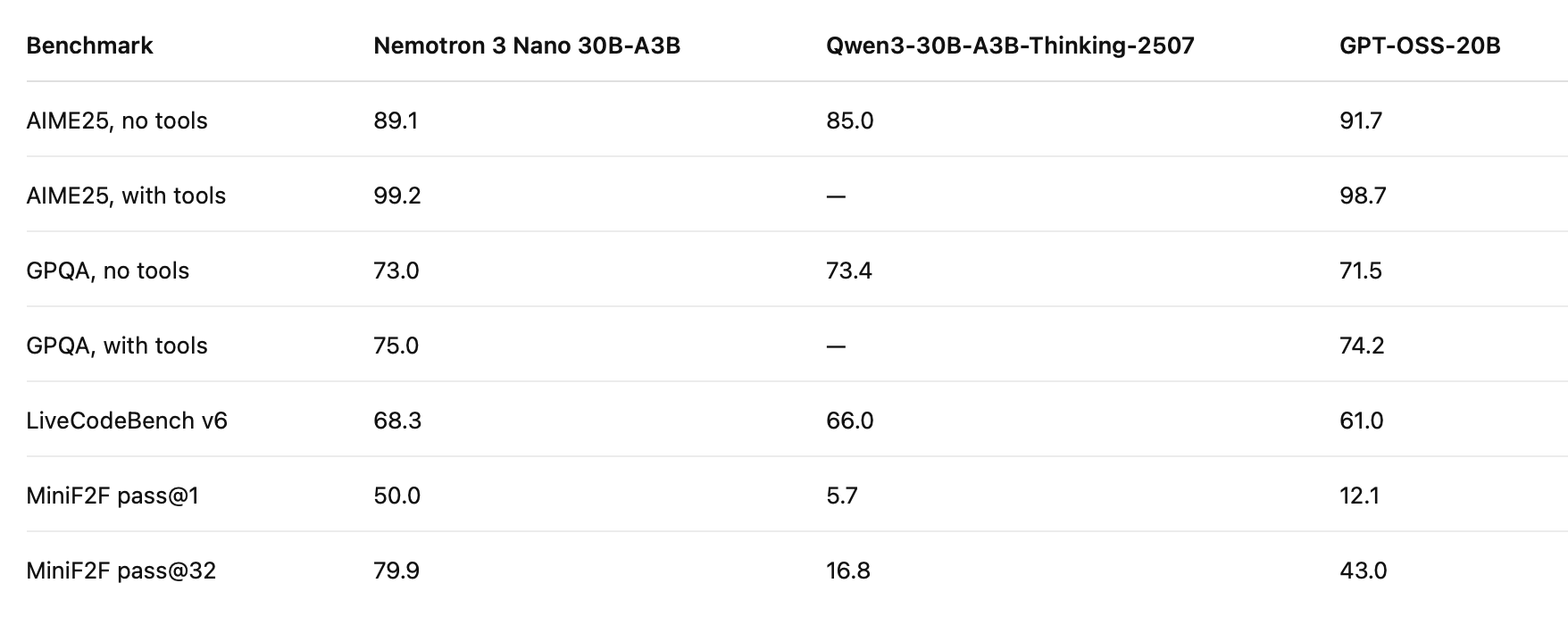
NVIDIA’s benchmark data shows Nemotron 3 Nano performing strongly across math, coding, and formal reasoning tasks, with especially large gains on MiniF2F compared with the listed baselines.
What this means for developers
Benchmarks are useful, but the practical question is simpler:
What can I build with this model?
Nemotron 3 Nano is a strong fit for workloads where teams need a model that can reason, follow instructions, write code, use tools, and handle longer context — without deploying a giant dense model.
Good use cases include:
AI coding assistants
Agentic workflows
RAG over large document collections
Private enterprise chat
Technical Q&A
Math-heavy and logic-heavy workflows
Long-context document analysis
Workflow automation agents
Internal developer tools
Customer support assistants with private data
If your application needs more than lightweight chat but you still care about inference cost, Nemotron 3 Nano is a practical model to evaluate.
Agentic and tool-use performance
Press enter or click to view image in full size
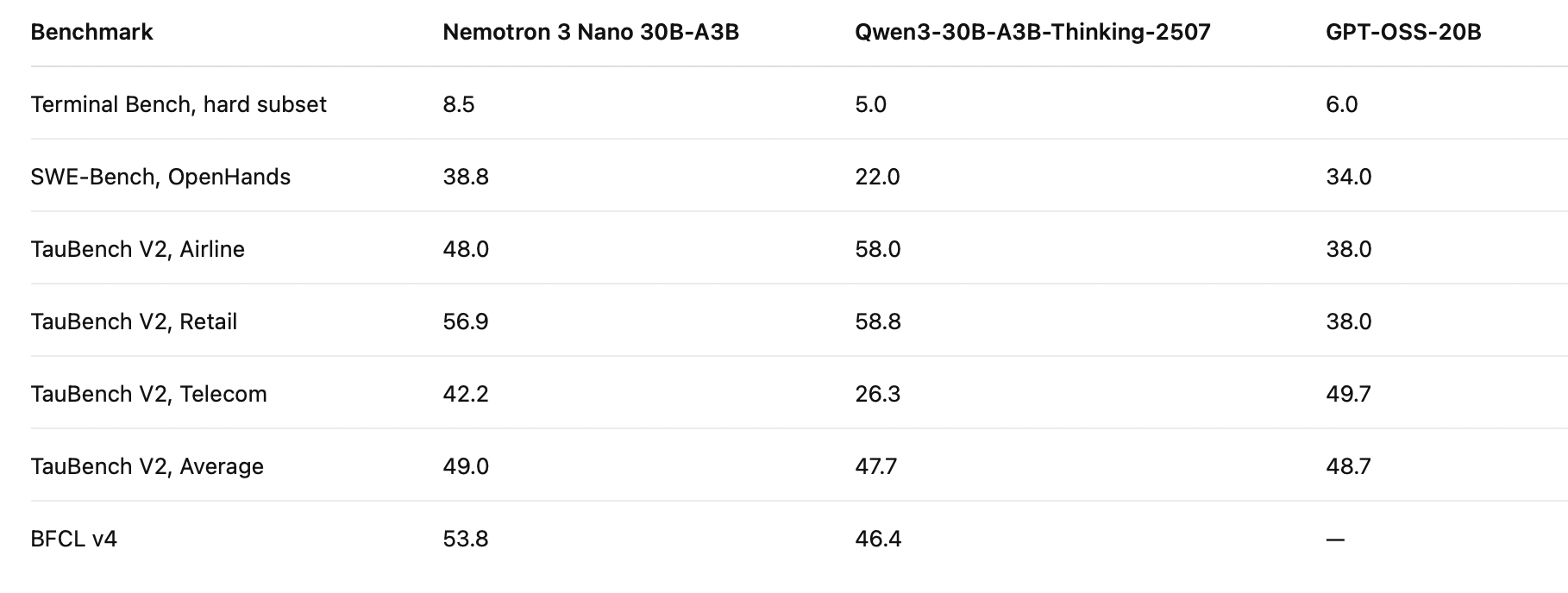
Result: Nemotron 3 Nano is competitive across agentic benchmarks, with strong results on SWE-Bench, Terminal Bench, TauBench average, and BFCL v4.
Built for agentic AI
The most important shift in AI applications is that models are no longer just answering questions. They are planning, calling tools, reading long context, generating code, debugging workflows, and acting as sub-agents inside larger systems.
NVIDIA positions Nemotron models as open models for building specialized AI agents.[¹]
That makes Nemotron 3 Nano especially relevant for teams building systems where the model needs to:
break down tasks,
reason through multi-step problems,
work with tools,
operate inside workflows,
analyze long context,
and produce structured outputs for downstream systems.
For many teams, this is the gap between a chatbot demo and a production AI application.
Instruction-following and chat quality
Press enter or click to view image in full size
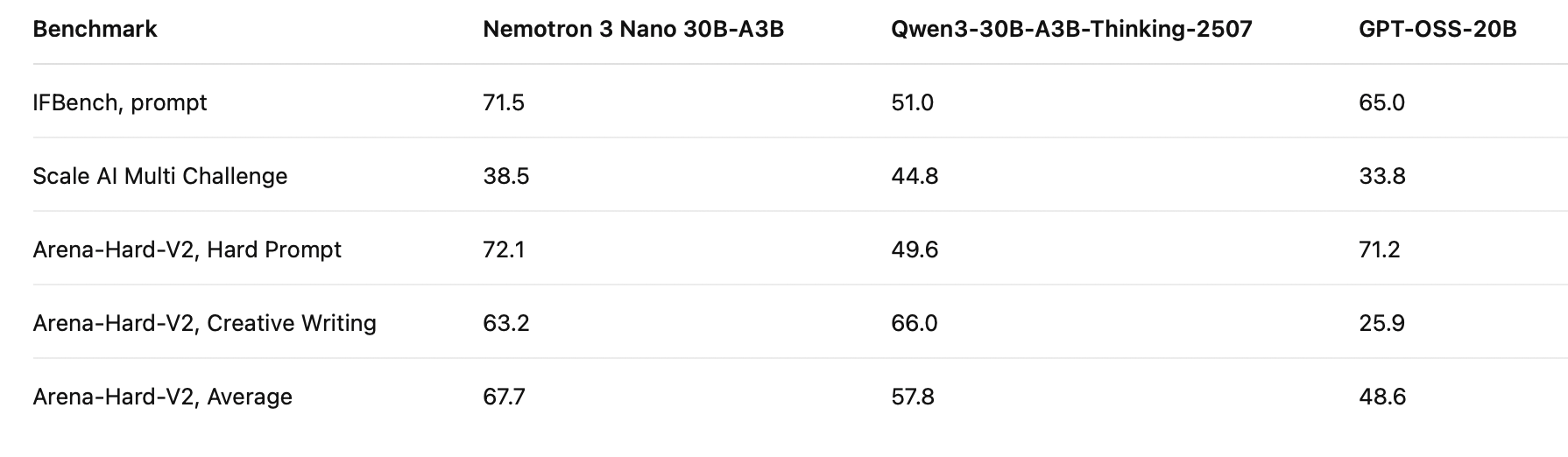
Result: Nemotron 3 Nano shows strong instruction-following and chat performance, including a 67.7 Arena-Hard-V2 average in NVIDIA’s published model-card results.
Long context: built for large inputs
Modern AI applications often need more than a short prompt.
A production model may need to reason over:
long contracts,
research papers,
support histories,
code repositories,
logs,
product documentation,
multi-turn agent memory,
or large retrieved context windows.
NVIDIA’s Nemotron 3 research page states that Nemotron 3 models support context length up to 1M tokens, and highlights Nemotron 3 Nano’s performance on long-context RULER evaluations.[³]
The Hugging Face model card reports the following RULER scores:
Press enter or click to view image in full size

Result: NVIDIA’s model-card results show Nemotron 3 Nano maintaining strong RULER scores from 256k to 1M context length
Throughput advantage
Performance is not only about benchmark accuracy. For production inference, throughput matters.
NVIDIA’s Nemotron 3 research page states that on an 8K input / 16K output setting with a single H200, Nemotron 3 Nano provides 3.3x higher inference throughput than Qwen3–30B-A3B and 2.2x higher throughput than GPT-OSS-20B.[³]
That matters because throughput directly affects:
user experience,
queueing delay,
infrastructure cost,
concurrency,
and how many requests your deployment can serve.
For production AI teams, a model that is both capable and efficient can be more valuable than a larger model that is harder to serve.
Why deploy Nemotron 3 Nano on HexGrid.cloud?
You can download open model weights yourself. You can run vLLM or SGLang yourself. You can provision GPUs yourself.
But then you own the entire infrastructure path.
That includes:
GPU provisioning,
runtime configuration,
model loading,
object storage,
HTTPS endpoint setup,
authentication,
logs,
usage tracking,
scaling,
billing visibility,
and production reliability.
HexGrid.cloud removes that operational overhead.
With HexGrid.cloud, Nemotron 3 Nano can be deployed as a private production endpoint on dedicated GPU infrastructure. Your app calls the model through the same OpenAI-compatible interface your existing tools already understand.
A typical request looks like this:
curl https://api.hexgrid.cloud/v1/chat/completions \
-H "Authorization: Bearer $HEXGRID_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "nemotron-3-nano-30b-a3b",
"messages": [
{
"role": "user",
"content": "Explain why hybrid MoE models are useful for efficient reasoning."
}
]
}'
Same interface.
Private runtime.
Dedicated GPU deployment.
Final thoughts
Nemotron 3 Nano 30B-A3B is one of the most interesting open models for teams that want strong reasoning without giving up deployment efficiency.
It brings together:
30B-class model capacity,
roughly 3B-class active-parameter efficiency,
reasoning and non-reasoning modes,
strong coding and math benchmark results,
competitive agentic performance,
long-context support up to 1M tokens,
and a practical path for production inference.
Now, with hexgrid.cloud, you can deploy it on dedicated GPUs behind a private OpenAI-compatible API endpoint in minutes.
If you are building agents, RAG systems, coding assistants, enterprise chat, or private AI applications, Nemotron 3 Nano is ready to test on hexgrid.cloud today.
Deploy NVIDIA Nemotron 3 Nano 30B-A3B on hexgrid.cloud and start building with private, production-ready open-source inference.
Footnotes
[¹]: NVIDIA Developer — NVIDIA Nemotron: https://developer.nvidia.com/topics/ai/nemotron
[²]: Hugging Face — NVIDIA-Nemotron-3-Nano-30B-A3B-BF16 model card: https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16
[³]: NVIDIA Research — Nemotron 3 Family of Models: https://research.nvidia.com/labs/nemotron/Nemotron-3/
[⁴]: NVIDIA NIM model card — nemotron-3-nano-30b-a3b: https://build.nvidia.com/nvidia/nemotron-3-nano-30b-a3b/modelcard
[⁵]: arXiv — “Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning”: https://arxiv.org/abs/2512.20848
[⁶]: Hugging Face — NVIDIA-Nemotron-3-Nano-30B-A3B-FP8 model card: https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8
[⁷]: hexgrid.cloud homepage: https://hexgrid.cloud/



